Microservices using Thrift RPC, Golang, and Nodejs (and GraphQL)
— Microservices — 19 min read
What YAMLs are to Kubernetes, RPCs are to Microservices
RPC is the best way for inter-service communication in a microservices architecture. It works similarly to how a local procedure would do. Simply call the function!
Apache Thrift
Apache Thrift is a complete RPC framework developed by Facebook and later came under the umbrella of the Apache Foundation. The most notable software which uses Apache Thrift (simply "thrift" henceforth) is Cassandra. Being a complete RPC framework, it provides both Interface Definition Language (IDL) in form of .thrift files and the communication protocol for defining the services.
gRPC is another (more) popular one, but it is not a complete RPC framework, as gRPC deals with just the communication aspect of services while the IDL is defined through Protobufs.
I chose thrift because I have worked with it extensively on a year-long project of mine (will update the blog with it soon). There are some pros and cons of using gRPC over Apache Thrift and vice versa, but that's a story for another day.
Why Golang "AND" Nodejs
I recently began learning Golang and wanted to expand my horizons by building some projects with it. Nodejs just because I am quite adept at it (I'd like to believe). Also, Nodejs has the best support for GraphQL because of Apollo GraphQL. The main advantage of using RPCs is that they enable communication between different languages, and I found them to be suitable to experiment with for the new language I am learning.
Directory structure
The project is out there on Github on branch v1.
- thrift-graphql-demo/ - service-gql/ - build/ // script to generate client and server stubs in Nodejs - deployments/ // contains Dockerfile - src/ // main application code including .thrift generated stubs, GraphQL schema, resolvers, etc - package.json - service-user/ - build/ // script to generate client and server stubs in Golang - deployments/ // contains Dockerfile - cmd/ // main application code - server implementation - internal/ // .thrift file and generated stubs - go.sum - go.mod - service-post/ - build/ // script to generate client and server stubs in Golang - deployments/ // contains Dockerfile - cmd/ // main application code - server implementation - internal/ // .thrift file and generated stubs - go.sum - go.mod - k8s/ // Bonus section - Deployment using Kubernetes - docker-compose.yamlThrift IDL
The idea is simple:
- service-user stores user-related information
- service-post stores posts from each user
- service-gql acts as an aggregator and API Gateway
Let's start by defining a simple implementation for each of the 2 thrift servers.
The following is the IDL for the service-user. It returns a PingResponse to the ping() procedure when called.
1namespace go user2namespace js user3
4typedef i32 int5
6struct PingResponse {7 1: optional string message8 2: optional int version9}10
11service UserService {12 PingResponse ping(),13}Similarly, the service-post IDL can be defined (just replace "user" with "ping").
Generating stubs
The stubs can be generated by running...
./build/thrift-gen.shWhich internally just has the following command with some helpers to create the directory beforehand.
thrift -r -out ./internal/thrift-rpc --gen go ./internal/thrift/user.thriftThis generates the following files and directory under the internal directory.
- internal/ - thrift/ // Contains .thrift file - thrift-rpc/user/ - user.go // the service definition, as in UserService, PostService... - user-consts.go // the structs and types defined in the IDL, as in PingResponse, int...For Golang specifically, 2 additional files are generated - user_service-remote.go which is a client. Pretty handy for testing purposes, though our client implementation will actually be in Nodejs in another directory.
In the service-gql, the same bash script will generate the stubs for Nodejs in the same way.
Golang implementation
Now that our stubs are generated, we can implement them. For the simple IDL that we have defined, it is quite easy. Inside the cmd directory, create the following folders and files...
- cmd/ - impl/ // implementation of the service procedure - handler.go // barebones handler - UserHandler, PostHandler - ping.go // implementation of the ping() procedure - server/ // thrift server, which will listen to incoming connections will reside - server.go // `RunServer` which takes in the protocols, transports, and handlers to create the socket - thrift/ // "package main" - main.go // takes in the address to listen on a flag and runs the `server.go`Handler
The handler is a simple struct to which the procedure implementations are added.
1// handler.go2package impl3
4type UserHandler struct{}5
6func NewUserHandler() *UserHandler {7 return &UserHandler{}8}ping() implementation
ping() is a simple function that takes in no parameters and returns a response of type PingResponse
1// ping.go2package impl3
4var ApiVersion user.Int5
6func (p *UserHandler) Ping(ctx context.Context) (*user.PingResponse, error) {7 message := "ping"8 log.Println(message)9
10 PingResponse := user.NewPingResponse()11 PingResponse.Message = &message12 PingResponse.Version = &ApiVersion13
14 return PingResponse, nil15}Note that ApiVersion is of type user.Int. This comes from the fact that we had declared int32 of all programming languages to be of type int in the IDL. I set its value in the main.go file.
Golang server
The server takes in transport (TTransportFactory), protocol (TProtocolFactory), address (string), and TLS enable (boolean) to create a socket listening on the port provided while running the program (next up).
Transport abstracts away the Serialisation and Deserialisation which happens in the system. Protocol is also an abstraction that defines the mechanism through which Serialisation and Deserialisation are done. To know more about the transport and protocol, I recommend going over to the official docs.
1//server.go2package server3
4func RunServer(transportFactory thrift.TTransportFactory, protocolFactory thrift.TProtocolFactory, addr string, secure bool) error {5 transport, err := thrift.NewTServerSocket(addr)6 if err != nil {7 return err8 }9
10 handler := impl.NewUserHandler()11 processor := user.NewUserServiceProcessor(handler)12 server := thrift.NewTSimpleServer4(processor, transport, transportFactory, protocolFactory)13
14 log.Printf("Starting simple thrift server on: %s\n", addr)15 return server.Serve()16}I have skipped enabling TLS in the server for this demo.
Running the Golang server
Now that everything is set up and ready to run. All we have to write is our main file. I take some flags to pass in the address to listen dynamically, which is defaulted to localhost:9090.
1// main.go2package main3
4var (5 addr = flag.String("addr", "localhost:9090", "Thrift Address to listen on")6)7
8var ApiVersion = 19
10func main() {11 flag.Parse()12
13 impl.ApiVersion = user.Int(ApiVersion)14
15 transportFactory := thrift.NewTBufferedTransportFactory(8192)16 protocolFactory := thrift.NewTCompactProtocolFactory()17
18 if err := server.RunServer(transportFactory, protocolFactory, *addr, false); err != nil {19 log.Println("error running thrift server: ", err)20 }21}Wow, that was super easy 🤪 (No?)! All that we have to do now is run the commands from the CLI.
Say the magic words after me! GO... RUN ...
$ go run ./cmd/thrift/main.go2020/05/15 00:33:15 Starting simple thrift server on: localhost:9090Now we replicate the same behaviour in service-post (for simplicity, just copy over the same files and replace "User" with "Post").
Apollo GraphQL
Now that our Thrift server is up and running. We have to implement the Client for it. We will use Nodejs for implementing GraphQL, which will act as an orchestrator for other services and should be the only exposed service. Let us begin!
I just want to point out that I have been using Nodejs for quite a few years now and I am a big fan of doing things in a "High cohesion and Low coupling" manner (or simply put - very modular).
Inside the src folder of service-gql, create the following files and folders...
- src/ - resolvers/ // GraphQL resolvers - post/ // resolver for service-post - post.js // aggregator for all PostService procedures - postPing.js // implementation of ping() for service-post - user/ // resolver for service-post - user.js // aggregator for all UserService procedures - userPing.js // implementation of ping() for service-user - resolvers.js // aggregator for resolvers of all services - thrift/ // generated thrift IDLs - thriftClients/ // UserService and PostService clients - typeDefs // schema definition by using `gql` string templates - user.js // schema definition for UserService - post.js // schema definition for PostService - typeDefs.js // aggregator for resolvers of all typeDefs - utils/ // helper functions like logger - app.js // the "main" file to runSchema definition
Let's get started with the typeDefs. I use Apollo GraphQL's gql string templates to create schema as it keeps
things extremely modular which enables easy modification at a later point in time.
1// typeDefs.js2const { gql } = require("apollo-server-express");3const user = require("./user");4const post = require("./post");5
6const base = gql`7 type PingResponse {8 message: String9 _version: Int10 }11
12 type Query {13 ping: PingResponse!14 }15`;16
17module.exports = [base, user, post];This is the "base" of the schema, things common to all services or otherwise should go here (like PingResponse). Unless PingResponse is going to change in either IDL, they should go into base, otherwise into their own files.
Let us extend this base to include the UserService and PostService details.
1// post.js2const { gql } = require("apollo-server-express");3
4module.exports = gql`5 extend type Query {6 postPing: PingResponse!7 }8`;// user.jsconst { gql } = require("apollo-server-express");
module.exports = gql` extend type Query { userPing: PingResponse! }`;Pretty simple huh? As the name suggests, the extend keyword in GraphQL includes it within the Query type of base. Now that we are done with defining our schema, let's get on with our resolvers.
Thrift Client implementation
The thrift IDLs are the same as those in other services (simply copied over) under the thrift/ directory. The stubs for Nodejs are generated by running the following command from the root of service-gql directory.
$ ./build/thrift-gen.shThe underlying command is similar to how it was for Golang. Now that the stubs are generated, let's proceed with the client implementation.
I will demonstrate UserService's client; PostService's is the same just with some variable name differences.
1// userClient.js2const thrift = require("thrift");3const UserService = require("../thrift/user/UserService");4const logger = require("../utils/logger");5
6const SERVER_HOST =7 process.env.SERVICE_USER_HOST || process.env.SERVICE_USER_CLUSTER_IP_SERVICE_SERVICE_HOST;8const SERVER_PORT = parseInt(process.env.SERVICE_USER_PORT);9
10logger.info(`userClient: ${SERVER_HOST} ${SERVER_PORT}`);11
12const thriftOptions = {13 transport: thrift.TBufferedTransport,14 protocol: thrift.TCompactProtocol15};16
17const connection = thrift.createConnection(SERVER_HOST, SERVER_PORT, thriftOptions);18let client;19
20connection.on("error", err => {21 logger.error(`userClient: ${JSON.stringify(err)}`);22});23
24connection.on("connect", () => {25 client = thrift.createClient(UserService, connection);26 logger.info("userClient: Connected to thrift server!");27});28
29connection.on("close", () => {30 logger.info("userClient: Disconnected from thrift server!");31 process.exit(1);32});33
34process.on("SIGTERM", connection.end);35
36/**37 * thrift user client38 * @param {string} func thrift function to call39 * @param {object[]} params params to pass to the thrift function40 */41const userClient = (func, params) =>42 new Promise((resolve, reject) => {43 client[func](...params)44 .then(resolve)45 .fail(reject);46 });47
48module.exports = userClient;That is some client, right?! I shall explain...
I fetch the SERVER_HOST and SERVER_POST from the environment variables.
The noticeable variable is process.env.SERVICE_USER_CLUSTER_IP_SERVICE_SERVICE_HOST I presume.
This is set in Kubernetes which is a part of the Bonus! section towards the end of the blog.
Otherwise, it is actually pretty straightforward, use the same transport and protocol as the thrift server, create a connection, and log valuable messages according to whether the connection was established or not. The reconnect strategy that I have chosen is - nothing! I hope that the application is deployed using Docker-Compose or Kubernetes which will make use of the process.exit(1); to trigger a rerun of the container in which this service resides.
The magic part here is the userClient variable. Do you know that everything is an object in Nodejs (almost everything)? I just make use of that. I wanted to keep things clean and as reusable as possible. Simply pass in the function name as a string and the params (just like in Golang) and call the function. Luckily, this looks easier and/or messier in Javascript. Its usage will be more clear in the next section.
Just a side note that Apache Thrift uses Q library which is archaic! From a time before Promises were natively part of Javascript Language Specification. So it actually wraps the Q promise returned by Thrift into a Native Promise. Neat right?
Resolvers implementation
The aggregator file resolvers.js goes like this...
1// resolvers.js2const _ = require("lodash");3const user = require("./user/user");4const post = require("./post/post");5
6const base = {7 Query: {8 ping: () => ({ message: "ping", _version: 1 })9 }10};11
12module.exports = _.merge(base, user, post);I use lodash's merge to combine Objects with same keys as we will see next in our implementation of UserService's resolver.
The UserService's user.js aggregator looks like this...
1// user.js2const userPing = require("./userPing");3
4module.exports = {5 Query: {6 userPing7 }8};Since this is the aggregator, the implementation actually lies in another file.
1// userPing.js2const userClient = require("../../thriftClients/user");3
4module.exports = async () => {5 try {6 const { message, version: _version } = await userClient("ping", []);7 return { message, _version };8 } catch (e) {9 throw e;10 }11};Here we make use of our thriftClient which I have described in the previous section.
Since ping() does not take in any param, I have passed an empty array. Otherwise, I would have passed an equal number of arguments as defined in the IDL (wrapped in desired class) AND in the same order.
You might wonder why try-catch when I am just throwing it right? It is just because in case I wanted to do some rollbacks in case of multi-service operations, I could depend upon the error message. That will be a blog post for another day though.
Now go on and do the same for PostService (just copy the files over and replace "user" with "post").
The legendary app.js
Now that all our services and their implementations have been defined. Let's get on with the implementation of the HTTP server. It uses express and apollo-server-express to run the server. Here goes the implementation...
1require("dotenv/config");2const express = require("express");3const compression = require("compression");4const bodyParser = require("body-parser");5const helmet = require("helmet");6const { ApolloServer } = require("apollo-server-express");7const typeDefs = require("./typeDefs/typeDefs");8const resolvers = require("./resolvers/resolvers");9const logger = require("./utils/logger");10
11const app = express();12
13app.set("port", process.env.GRAPHQL_PORT);14app.use(compression());15app.use(bodyParser.json());16app.use(bodyParser.urlencoded({ extended: true }));17app.use(helmet());18
19app.get("/healthz", (_req, res) => {20 res.json({21 health: "ok",22 version: 123 });24});25
26const apolloServer = new ApolloServer({27 typeDefs,28 resolvers,29 formatResponse: response => {30 logger.info(JSON.stringify(response));31 return response;32 },33 formatError: error => {34 logger.error(JSON.stringify(error));35 return error;36 }37});38
39apolloServer.applyMiddleware({ app, path: "/" });40
41/** Start Express server. */42const server = app.listen(app.get("port"), () => {43 console.log(44 " App is running at http://localhost:%d in %s mode",45 app.get("port"),46 app.get("env")47 );48 console.log(" Press CTRL-C to stop\n");49});50
51module.exports = { app, server };If you are familiar with express then this will be self-explanatory.
I will only point out the fact that to run the server, necessary environment variables like GRAPHQL_PORT have to be defined. To make life easier, I make use of the dotenv package which loads environment variables at runtime into the application from a special .env file. So let's define that in the root of service-gql directory.
1GRAPHQL_PORT=30002SERVICE_USER_HOST=localhost3SERVICE_USER_PORT=90904SERVICE_POST_HOST=localhost5SERVICE_POST_PORT=9091This considers that the service-user is running on localhost:9090 and service-post is running on localhost:9091.
Now start the thrift servers and then let's run this server...
$ npm start # essentially running app.js> service-gql@0.0.1 start /home/nsinvhal/Workspace/Go/src/github.com/ashniu123/thrift-graphql-demo/service-gql> node src/app.js
(59254) [2020-05-15T17:29:27.651Z] info: userClient: localhost 9090(59254) [2020-05-15T17:29:27.668Z] info: postClient: localhost 9091 App is running at http://localhost:3000 in development mode Press CTRL-C to stop
(59254) [2020-05-15T17:29:27.752Z] info: userClient: Connected to thrift server!(59254) [2020-05-15T17:29:27.753Z] info: postClient: Connected to thrift server!Voila! All services are connected and running, exposed through a GraphQL server.

Since this is running in development mode. We can go ahead and check the Apollo GraphQL playground and see it in action!
Here is a screenshot of it in action!
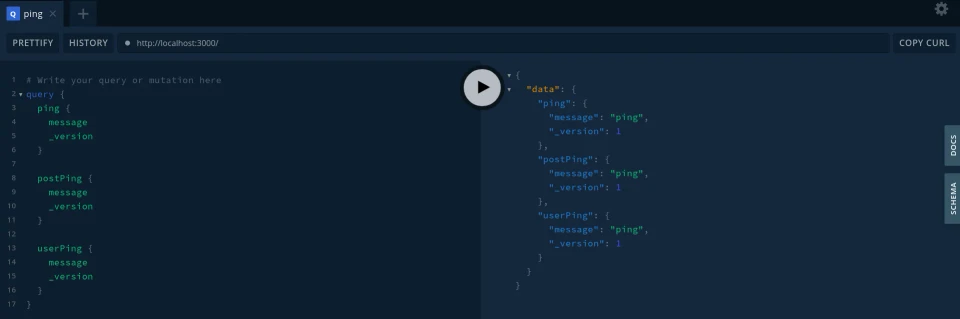
Go ahead and try it yourself!
Final Words
This has been quite a long post and might seem too much just to implement a simple ping() function between 2 services. I would not disagree, but consider the following fact - the skeleton has been laid out! Now adding more procedures anywhere is a piece of cake! All you have to do is to do the following...
- Update the .thrift file and generate stubs through the
thrift-gen.shfile - Copy the thrift definition over to service-gql and run the same file as above
- Add server implementation in Golang
- Add typeDefs and resolvers in Nodejs
That's it! And this is replicable for any other service(s) you might want to add.
Bonus: Deployment
Now let's get onto the deployment part. How do we deploy these microservices? I'll show 2 ways - one with Docker-Compose and the other with Kubernetes.
Bonus: Deploy using Docker-Compose
Docker-Compose is an amazing tool that can be used to quickly test out interconnected Docker containers. Although Docker Swarm can be used to mimic this in production, with the arrival of Kubernetes, this strategy is not popular.
Dockerfile
First we have to define the Dockerfile. It lies in the deployments folder of each service.
The Dockerfile for the service-user/post goes like this...
1FROM golang:alpine2
3RUN apk add --no-cache git gcc musl-dev4
5WORKDIR /usr/app6
7COPY . .8
9RUN go mod download && go build -o main.o ./cmd/thrift10
11EXPOSE 909012
13ENTRYPOINT ["/usr/app/main.o"]Pretty simple right? Well, the image size after this is a mind-boggling 450MiB. To decrease it, we can use multi-stage builds with the actual image using scratch image which contains just the binary from the builder stage. Something to try out yourself.
Similarly, we define the Dockerfile for our service-gql.
1FROM node:alpine2
3WORKDIR /usr/app4
5COPY ./package.json .6
7COPY ./package-lock.json .8
9RUN npm install --production10
11COPY ./src ./src12
13EXPOSE 300014
15CMD ["npm", "start", "--production"]This image makes good use of the caching strategy of Docker for subsequent builds.
Now let's define our docker-compose.yaml file in the root of the project directory.
1version: "3"2services:3 service-user:4 build:5 context: ./service-user6 dockerfile: ./deployments/Dockerfile7 restart: unless-stopped8 command: -addr service-user:90909 ports:10 - 9090:909011
12 service-post:13 build:14 context: ./service-post15 dockerfile: ./deployments/Dockerfile16 restart: unless-stopped17 command: -addr service-post:909018 ports:19 - 9091:909020
21 service-gql:22 build:23 context: ./service-gql24 dockerfile: ./deployments/Dockerfile25 restart: unless-stopped26 ports:27 - 3000:300028 depends_on:29 - service-user30 - service-post31 environment:32 - GRAPHQL_PORT=300033 - SERVICE_USER_HOST=service-user34 - SERVICE_USER_PORT=909035 - SERVICE_POST_HOST=service-post36 - SERVICE_POST_PORT=9090I pass arguments to Golang servers since they have to connect to the default network Docker-Compose creates, and add a dependency for service-gql on other one's services with proper environment variables.
Now let's give it a shot!
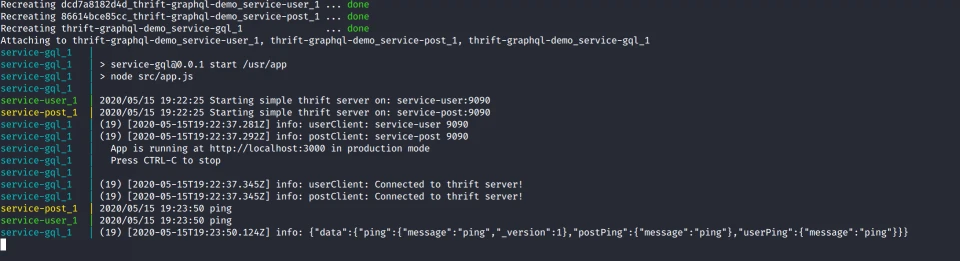
$ docker-compose upIn the very first run, it will build the images, which will be used in subsequent runs. Here is a screenshot of how it looks in action.
Bonus: Deploy using Kubernetes
This is yet another section for deploying microservices using Kubernetes. To keep things easy, I will be using minikube.
As soon as you start minikube, be sure to enable the ingress addon with the following command...
$ minikube addons enable ingressThis will enable ingress and will enable us to use the ingress-nginx load-balancer to route external traffic to GraphQL. At the same time, be sure to install the ingress-nginx load-balancer from here.
Here is what the cluster should look like at the end of our deployments...
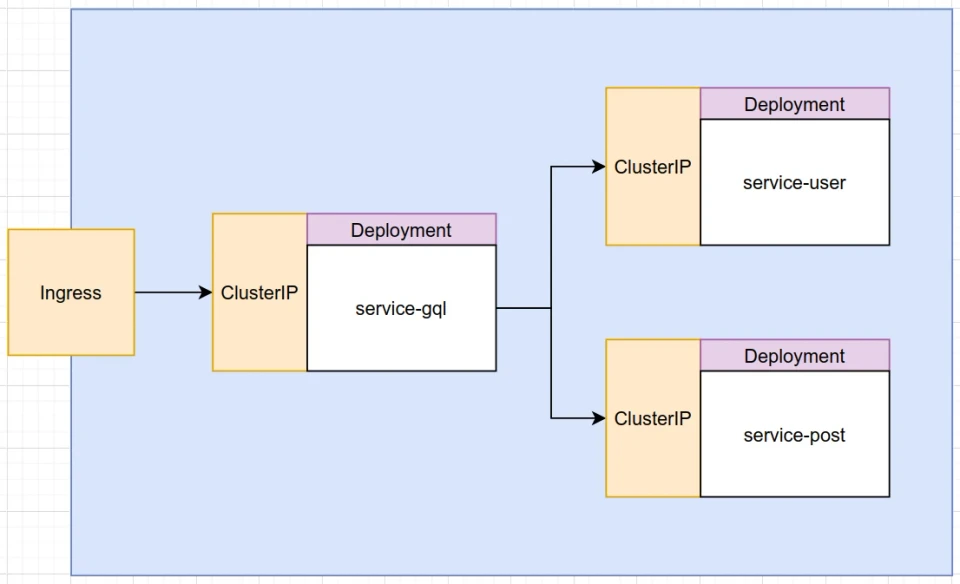
Now let's get started.
Ingress
Ingress is used to manage the flow of external traffic to services within our cluster. We will define a simple ingress-service.yaml which will direct the flow of all traffic ending with /graphql to service-gql on port 3000. Other services (user and post) will not be accessible outside directly, but only through GraphQL (as intended).
1# ingress-service.yaml2apiVersion: networking.k8s.io/v1beta13kind: Ingress4metadata:5 name: ingress-service6 annotations:7 kubernetes.io/ingress.class: nginx8spec:9 rules:10 - http:11 paths:12 - path: /graphql13 backend:14 serviceName: service-gql-cluster-ip15 servicePort: 3000The annotation implies that we wish to use the infamous Nginx load-balancer.
Defining Deployments
Deployment is the go to way of deploying Pods in a k8s cluster. Let's start by defining the YAML for service-user. The same YAML can be used for service-post too (just be sure to change the names).
1# service-user-deployment.yaml2apiVersion: apps/v13kind: Deployment4metadata:5 name: service-user-deployment6spec:7 replicas: 18 selector:9 matchLabels:10 app: service-user11 template:12 metadata:13 labels:14 app: service-user15 spec:16 containers:17 - name: service-user18 image: ashniu123/thrift-graphql-demo-service-user:v119 args:20 - -addr=:909021 resources:22 limits:23 memory: "128Mi"24 cpu: "250m"25 ports:26 - containerPort: 9090Please note that k8s does not build containers like docker-compose does, so you will need to push a built image somewhere (popularly on Docker Hub).
Now let's create service-gql's Deployment. The only difference is that it will include the environment variables that we had passed in the .env file or otherwise. And the fact that the host of the services won't be localhost anymore but the ClusterIP Service we are going to define in the next section.
1# service-gql-deployment.yaml2apiVersion: apps/v13kind: Deployment4metadata:5 name: service-gql-deployment6spec:7 replicas: 18 selector:9 matchLabels:10 app: service-gql11 template:12 metadata:13 labels:14 app: service-gql15 spec:16 containers:17 - name: service-gql18 image: ashniu123/thrift-graphql-demo-service-gql:v119 resources:20 limits:21 memory: "512Mi"22 cpu: "250m"23 ports:24 - containerPort: 300025 env:26 - name: GRAPHQL_PORT27 value: "3000"28 - name: SERVICE_USER_HOST29 value: service-user-cluster-ip30 - name: SERVICE_USER_PORT31 value: "9090"32 - name: SERVICE_POST_HOST33 value: service-post-cluster-ip34 - name: SERVICE_POST_PORT35 value: "9090"Defining ClusterIP Service
ClusterIP Service is used to expose a Pod into the cluster so that it is accessible by other services (as seen in the YAMLs above). The YAML's structure is the same for all services. Below is the service-gql ClusterIP Service.
1# service-gql-cluster-ip.yaml2apiVersion: v13kind: Service4metadata:5 name: service-gql-cluster-ip6spec:7 type: ClusterIP8 ports:9 - port: 300010 targetPort: 300011 selector:12 app: service-gqlThe port is what will be exposed within the Cluster and targetPort is the port in the container which the ClusterIP has to expose.
Now let's go up a directory and apply all YAMLs at once.
$ kubectl apply -R -f k8s/Here is a screenshot of all Objects running in my minikube.
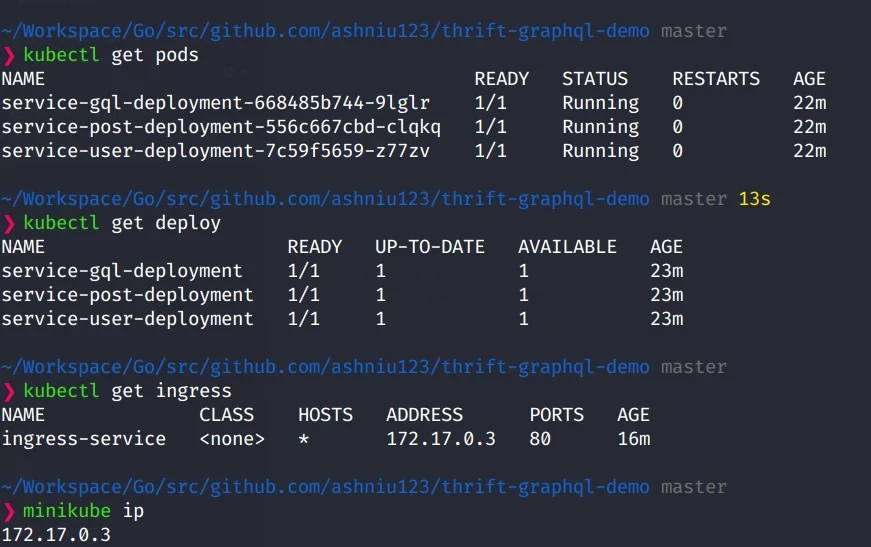
And here is working with Insomnia client. Be sure to run minikube ip to get the ip of the
Cluster as localhost:3000 will not show anything.
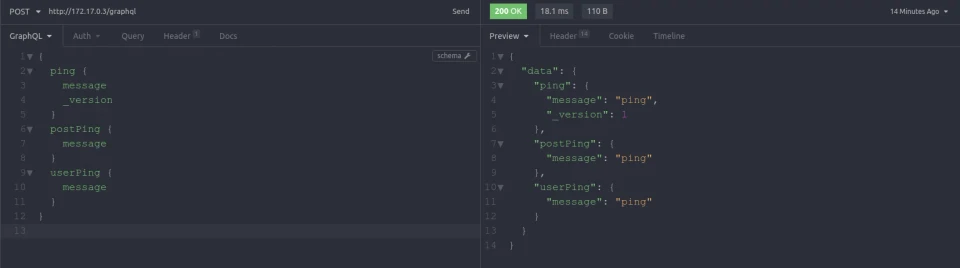
Amazing right?